
参照型編
今回は新人プログラマにとって分かりにくい「参照型」について見ていきましょう。
Java言語の型には基本型と参照型の二種類がありますが、変数の使い方はどちらも同じなのに何が違うのですか?
そう、その”使い方が同じ”というのがつまずきポイントの一因にもなっていますね。
基本型も参照型も変数の使い方が全く同じなのでプログラマ自身が参照型を意識しないと思わぬ不具合を生み出してしまうのです。
思わぬ不具合って具体的にどんな不具合でしょうか?
例えば、更新してはいけないオブジェクトの中身を更新してしまったり、逆に更新していると思っていたのに更新できていなかったり、といった不具合ですね。
自分でプログラムを書いているのにそんなことが起きるんですね?
特にライブラリのAPIを使用する場合、ライブラリの実装までは確認しませんから、きちんとAPI仕様をみないと先ほど言った不具合を生んでしまうのです。
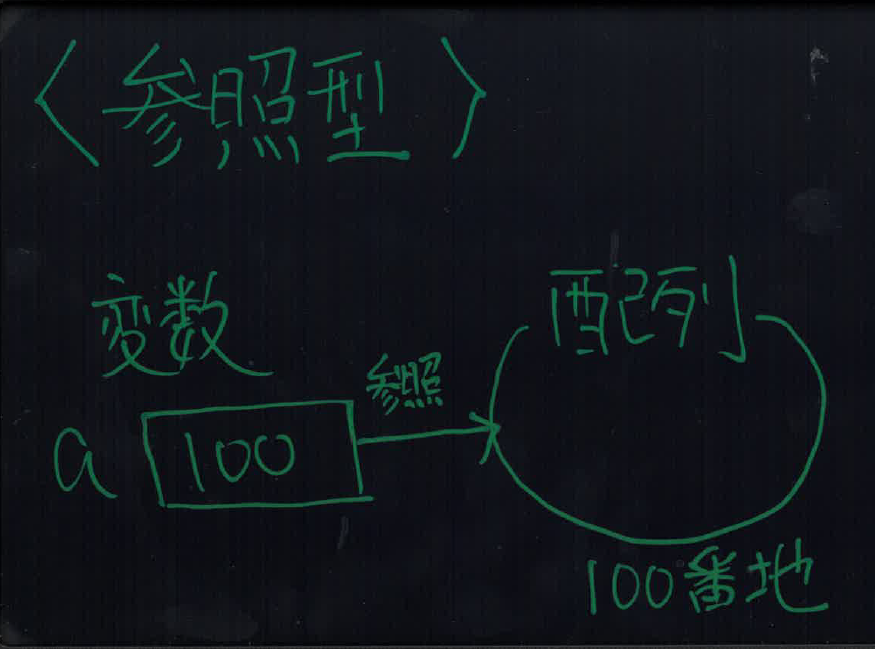
参照型はややこしいのですが、仕組みはすごくシンプルで、データそのものを扱うのではなくデータのアドレスを扱う、という仕組みです。ただし、きちんと理解しないと参照型を使いこなすのが難しいのも事実です。コンピュータがどのようにデータを扱うのかを正しくイメージできるようにしましょう。
変数と型について
プログラムは「データ」と「命令」の集まりです。プログラムでデータを扱うときに使うのが「変数」ですね。変数はよく「データを入れる箱」と表現されますが、もう少し正確にいうと変数は「メモリ上のある領域」を指しています。その領域のアドレスを抽象化しているのが変数名ということです。
データは変数に格納します。その際にデータの大きさが決まらないと変数の大きさも決められません。我々の日常で例えると、物を持ち運ぶときに鞄を使いますね。「物」が「データ」、「鞄」が「変数」に相当します。どの鞄を持っていくかは中に入れる物によって決めると思います。コンピュータでも同じようにデータを入れるためにはデータが十分入る箱(変数)を用意する必要があります。その大きさを決めるのが「型」になります。実は型の役割は「大きさを決める」だけでなく、「振る舞いを決める」というもっと重要な役割も持っているのですが、ここでは大きさのことだけを考えます。
プログラミング言語では「型」は基本型(プリミティブ型)と参照型の二種類に分けられています。ただしPythonのように参照型しかないプログラミング言語もあります。まずはこの二種類の型の違いについて見てみましょう。
データが直接変数に格納される
データは別の場所に存在し、変数にはそのデータのアドレスが格納される
基本型はイメージしやすいと思います。鞄(変数)の中にじかに物(データ)が入っているからです。一方の参照型は鞄の中を覗いてみても実際の物は入っておらず、物が置いてある住所を記した紙しか入っていないのです。つまり物が置いてある場所まで移動しないと物を見たり、触ったりできないということです。
参照型で注意しなければいけないのは「変数の中には直接データは入っておらず、データが存在するアドレスの値が入っている」の一点です。
ただし冒頭でも申し上げた通り、例えばJavaでは、参照型変数の宣言・参照・代入のいずれの操作も基本型変数と全く同じです。つまりプログラマ自身が参照型か基本型かを意識する必要があります。
値渡しと参照渡し
冒頭の会話で「参照型では思わぬ不具合を生む」とありましたが、その原因の多くはプログラマが変数を参照したり、代入したりするときに「値渡し」か「参照渡し」かを把握できていないからです。では「値渡し」と「参照渡し」とはどういった振る舞いのことを言うのでしょうか?
いきなり問題ですが、次のプログラムを実行したときに何が表示されるか分かるでしょうか?
public class SampleCode1 {
public static void main(String[] args) {
int a = 10;
add(a);
System.out.println(a);
}
public static void add(int a) {
a = a + 10;
}
}では、次のプログラムでは如何でしょうか?
public class SampleCode2 {
public static void main(String[] args) {
int[] a = {10};
add(a);
System.out.println(a[0]);
}
public static void add(int[] a) {
a[0] = a[0] + 10;
}
}答えは前者が「10」と表示され、後者は「20」と表示されます。
ポイントは変数の値をメソッドの引数に渡すときの値が何であるか、です。
どちらも正解だった方は基本型と参照型の違いをきちんと理解できていると思います。どちらか一方、あるいは両方とも不正解だった方はまだ基本型と参照型の振る舞いをきちんと理解できていないかもしれません。
処理の実行順に何が行われているかを見ていきましょう。
SampleCode1のコード解説
int a = 10;
基本型の変数aを宣言し、aの変数の中に直接「10」というデータが代入されます。
add(a);
addメソッドが呼び出され、「a」という名前で引数が宣言され、その引数に変数aの値である10が代入(コピー)されます。
a = a + 10;
引数aに10を足して、その結果である20という値を同じ引数aに上書きします。addメソッドの処理が終わると呼び出し元へと戻ります。
System.out.println(a);
System.out.printlnで変数aを表示していますが、この変数は10が代入されたままですので、「10」が表示されます。
SampleCode2のコード解説
int[] a = {10};
10という値の要素を1つ持った配列のインスタンスが生成され、そのインスタンスのアドレスが変数aに代入されます。
add(a);
addメソッドが呼び出されるときに配列型の引数aが宣言され、変数aの中に入っている値である配列のアドレスが引数aに渡されます。
a[0] = a[0] + 10;
配列の0番目の要素に10を足して、その結果である20という値を同じ0番目の要素に上書きします。addメソッドの処理が終わると呼び出し元へと戻ります。
System.out.println(a[0]);
System.out.printlnで配列の0番目の要素を表示していますが、この要素はaddメソッド内で20で上書きされたため「20」が表示されます。
1ステップごとに何が行われているかを詳しく見ていきました。値渡しと参照渡しの違いがお分かりいただけたでしょうか?
今回はみなさんを混乱させるため、意図的に変数名と引数名を同じ名前で宣言しています。本来はこのような変数名は使いませんが、ご容赦ください。
もっとも重要なポイントをまとめると、
SampleCode1では変数aと引数aは別の場所にある入れ物なので、引数aの値が更新されても変数aにはまったく影響しない
SampleCode2では変数aと引数aは別の場所にある入れ物ですが、お互い同じインスタンス(配列)のアドレスを参照しているため、引数a経由で配列の要素が更新されると、同じインスタンスを参照している変数aにも影響が出てしまう
ということになります。これが基本型と参照型の違いになります。
Javaから見ると変数から別に変数に代入するときは変数の中身の値をコピーするだけですので、値渡しだろうが参照渡しだろうがやっていることは同じなのですが、渡す内容が単なる値なのか参照先のアドレスなのかでその後の振る舞いが全く変わってくるためプログラマは注意が必要なのです。
なぜ参照型があるのか
たくさんの人が参照型を理解するのに苦労し、何度も失敗が重ねられているにも関わらず、なぜ参照型のようなややこしい仕組みが用意されいるのでしょうか?それはコンピュータにとって参照型でデータを扱う方が基本型で扱うより断然効率が良いからです。コンピュータで効率が良いとは「メモリ消費量が小さい」ことと「処理速度が速い」ことです。
基本型の場合、変数から別の変数に値を代入する場合、データ自体をコピーすることになります。つまりデータが1Byteであれば、1Byte分のコピー、仮にデータが1GBであれば1GB分のコピーになってしまいます。これだとコピー先の変数も1GB分の容量が必要ですし、1GB分をコピーするのも相当時間が掛かってしまい効率が悪いですね。
ところが参照型の場合はデータ自体をコピーするのではなく、データのアドレスをコピーすることになるため、アドレスの大きさ分(例えば64Bitなど)のコピーで済むのです。仮にインスタンスの大きさが1GBだったとしても、実際にコピーするのはたった8Byteで済むことになります。これは凄く効率の良いデータの扱い方ですよね。
図書館にある本を1冊読みたいだけなのに、基本型の世界だと、図書館ごと自分の手元に持ってくることになってしまうのですが、参照型の世界では図書館の住所をもらうだけ済むということになります。つまり参照型の仕組みは大容量のデータを効率的に扱うために用意されているということです。
プログラムでは10や20といった単なる数値を扱うこともあれば、大容量のデータを扱うこともあります。いやむしろ大容量のデータを扱うことの方が多いのですから、参照型という仕組みが必要なんですね。
まとめ
参照型はデータそのものを直接扱うのではなく、データのアドレスを扱う、という仕組みを持った型のことでした。我々の世界でも誰かの住所がもし世界中の人に知られてしまったら、世界中の人がやってくることになります。考えただけで恐ろしいですね。これと同じことが参照型の変数を使うたびに毎回発生しています。同じアドレスを持った変数が複数あった場合、それらすべての変数から同じデータを読んだり、書いたり出来ることになってしまいます。やっぱり恐ろしいことですね。
ただし、参照型を上手く使いこなせば、複数の変数からデータを共有できるため、便利な面もあります。ライブラリでは参照型を扱うAPIがほとんどですが、それはこのメリットがあるからです。ただし、何度も言うように参照型のデータを扱っていることをプログラマが意識しないといけないデメリットもあります。新人プログラマから一歩抜け出すためにも参照型をしっかりとマスターしましょう。
さいごに
この記事を読んでも参照型についてピンと来ない方もいらっしゃるかもしれません。プログラマはたくさん失敗した方が早く技術が身に付きますし、成長すると思います。現場で思いっ切り失敗してください。今はピンと来なくても、いずれ分かるときが来ると思いますので。自ら失敗して学ぶことが一番早く技術を身に付ける方法かもしれませんね。

